12399456https://www.upal.com.my/zh/feeds/jobFeedKwongwahArray
(
[0] => HTTP/1.1 200 OK
[1] => Date: Fri, 26 Jun 2026 08:35:29 GMT
[2] => Content-Type: text/xml; charset=utf-8
[3] => Connection: close
[4] => Cache-Control: no-cache, private
[5] => Cache-Control: no-cache, no-store, must-revalidate
[6] => Set-Cookie: UpalLiveSession=eyJpdiI6IkdkWGp5aFwvWW9uam9wNFF0QzE5Q1J3PT0iLCJ2YWx1ZSI6IjVVUUVQT3psblRWdnkwZDhuVDFpRlp4S0NyMzRyTFUwanhEdDZ5cTJ5XC9lNldKWXNYZVIrNlBLS0t1ZjhJU2NrQVdrTFdBbzNcLzhURmFtY2FJenE5dUE9PSIsIm1hYyI6ImI2OThlMTlmYWE2NjQ0NDcwZGM1YWE2ZDBmM2M4NTk0ZDdhMjhmZGMxNDUxMzdjOTQ3MWIwMmY2NmVhYjg3MGYifQ%3D%3D; expires=Mon, 25-Jun-2029 08:35:28 GMT; Max-Age=94608000; path=/; HttpOnly
[7] => X-Frame-Options: SAMEORIGIN
[8] => X-Content-Type-Options: nosniff
[9] => X-Xss-Protection: 1; mode=block
[10] => Referrer-Policy: strict-origin-when-cross-origin
[11] => Permissions-Policy: geolocation=(), microphone=(), camera=()
[12] => Content-Security-Policy: default-src * 'unsafe-inline' 'unsafe-eval' data: blob:; script-src * 'unsafe-inline' 'unsafe-eval' data: blob:; style-src * 'unsafe-inline' data:; img-src * data: blob:; font-src * data:; connect-src *; frame-src *; object-src *; media-src *; child-src *;
[13] => Server: cloudflare
[14] => X-Robots-Tag: noindex, nofollow, nosnippet, noarchive
[15] => Strict-Transport-Security: max-age=31536000; includeSubDomains; preload
[16] => Expires: Sat, 27 Jun 2026 08:35:28 GMT
[17] => Vary: Accept-Encoding
[18] => Nel: {"report_to":"cf-nel","success_fraction":0.0,"max_age":604800}
[19] => Cf-Cache-Status: DYNAMIC
[20] => Speculation-Rules: "/cdn-cgi/speculation"
[21] => Server-Timing: cfCacheStatus;desc="DYNAMIC"
[22] => Server-Timing: cfEdge;dur=9,cfOrigin;dur=769
[23] => Report-To: {"group":"cf-nel","max_age":604800,"endpoints":[{"url":"https://a.nel.cloudflare.com/report/v4?s=SSpR2Mj2K90qD8nR%2BjKphDIJoqxySlyNZjpKhFpgDVGNW0jRXkpmHXKySemCOK3I%2Fh4v7vuai7EItTUJmo64i5r%2FLLlrQKisPl9ytk90HJr21FeNIqGNVX%2BHFly9opuKYOc%3D"}]}
[24] => CF-RAY: a11ae0f5bbf65654-LAX
[25] => alt-svc: h3=":443"; ma=86400
)
789

声音可以暴露很多信息,比如说,广东人跟东北人讲的中文永远都不是一个味儿。而麻省理工学院(MIT)最近一项研究发现,经过训练的 AI 不仅能从声音里辨别出你的性别、年龄和种族,甚至能猜出你大概长什么样。这些“秘密”都藏不住了。
 Speech2Face 的一些错误示例。
Speech2Face 的一些错误示例。
研究人员用一个由数百万YouTube视频剪辑组成的数据集,对一个名为 Speech2Face 的神经网络模型进行自我训练,从最终结果来看,6秒语音对人脸进行还原的效果还算不错。
Speech2Face 模型的运作大概分为两部分,一个是语音编码器,负责对输入的语音进行分析,预测出相关的面部特征;另一个则是面部解码器,对输入的面部特征进行整合产生图像。
MIT 研究团队指出,他们的目的不是为了准确地还原说话者的模样,Speech2Face 模型主要是为了研究语音跟相貌之间的相关性。
 一共 6 组结果示例,左边是视频里的人像,右边是 AI 根据声音还原的效果。
一共 6 组结果示例,左边是视频里的人像,右边是 AI 根据声音还原的效果。
从训练结果看,Speech2Face能较好地识别出性别,对白种人和亚洲人也能较好地分辨出来,另外对30-40岁和70 岁的年龄段声音命中率稍微高一些。
除了比较基础的性别、年龄和种族,Speech2Face甚至能猜中一些面部特征,比如说鼻子的结构、嘴唇的厚度和形状、咬合情况,以及大概的面部骨架。基本上输入的语音时间越长,AI 的准确度会越高。
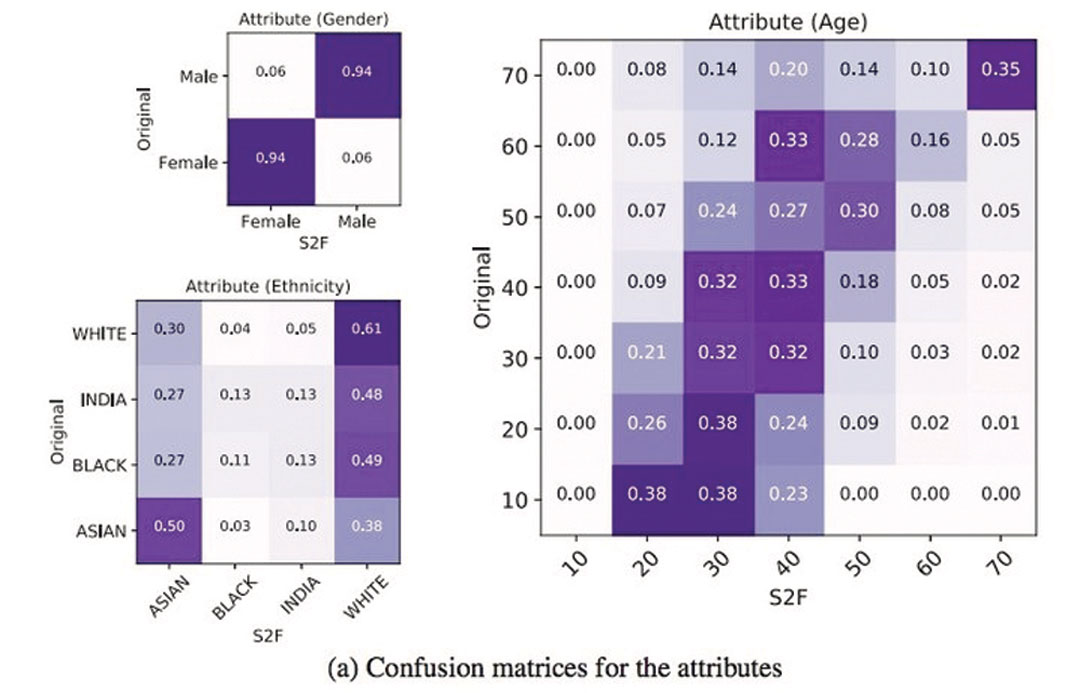 Speech2Face 似乎倾向将 30 岁以下的说话者年龄猜大,将 40-70 岁的说话者年龄猜小。
Speech2Face 似乎倾向将 30 岁以下的说话者年龄猜大,将 40-70 岁的说话者年龄猜小。
当然 AI 的“听觉”也会出错。研究人员发现,它会将未经历变声期的小男孩识别为女性,对一些说话者的口音判断错误,也会搞混年纪……这一点完全可以理解,毕竟声音还是会骗人的。
研究人员指出,Speech2Face 的局限性,部分原因来自数据集里的说话者本身种族多样性不够丰富,这也导致了它辨认黑种人声音的能力比较弱。
至于他们对这个 AI 模型的应用,则有一个很可爱的想象:只需要说几句话,未来 Animoji 和 Gboard 等功能或许就能根据声音生成你的卡通头像。不管你信或不信,藏在我们声音的秘密都正被开发研究,投入各式各样的场景应用。
卡内基梅隆大学计算机副教授 Rita Singh 也主导过一项类似的研究,能从声音猜测说话者的年龄、身高、体重、环境噪音和说话时的空间类型等信息。她认为声音里藏着丰富而独特的信息,“就像是你的 DNA 或指纹”。
这项技术后来升级成跟 Speech2Face 相似的语音分析系统,还原人脸的准确度达到 60%-70%,目前正被美国海岸警卫队用于缩小调查范围找到恶作剧报警者。据称,他们每年会接到约 150 个恶作剧电话,这些行为被视作浪费警力,甚至会遭到刑事起诉。
目前,汇丰(HSBC)、渣打(Standard Chartered)、摩根大通(JPMorgan Chase)等银行都在用“声纹”作为身份识别的一种方式(voice ID),可以检测你的账户是否被盗。
大都会人寿保险公司的客服中心,会用一套 AI 系统帮忙识别客户的情绪和感受,平均准确率达到 82%;一些保险公司甚至会借此判断来电者有没有骗保的意图——如果说话时出现微小停顿,很可能就是在提供虚假信息。
除此之外,经过训练的 AI 还被一些公司用于招聘,从应聘者的说话模式分析出性格特征,判断是否适合在招岗位。
而丰田(Toyota)汽车曾经在 2017 年 CES 大会展出 Concept-i 概念车型,车内配备红外摄像头、传感器、车载语音识别和对话系统,它们将协作判断司机是不是处于疲劳驾驶状态并作出提醒。

跟 MIT 的卡通头像相比,Singh 教授的想法似乎要更长远且宏大一些。她希望,有朝一日语音识别技术可以用于远程确诊帕金森等疾病。
而目前已经有研究发现,冠状动脉疾病患者在声音上会留有不同的频率标志。未来,“听声看病”说不定也会跟“听声识脸”一样成真。
找工作, 就找这里!

› 立即申请
- GMBB Part Timer
- Event
- Kuala Lumpur
-

MYR 110.00 /Month
› 立即申请
- Social Media Marketing Executive
- Advertising & Marketing
- Kuala Lumpur
-
MYR 6K /Month
› 立即申请
- PHP Software Developer
- Information Technology
- Wilayah Persekutuan
-
MYR 6K /Month
› 立即申请
- DevOps Software Engineer
- Information Technology
- Kuala Lumpur
-
MYR 6.5K /Month
› 立即申请
- Java Software Engineer
- Information Technology
- Kuala Lumpur
-
MYR 10K /Month
› 立即申请
- 软件测试与客户支持专员 Software Testing & Customer Support Specialist
- Information Technology
- Kuala Lumpur
-
MYR 3K /Month
› 立即申请
- PHP Web Developer (Internship)
- Engineering
- Kuala Lumpur
-
MYR 800.00 /Month
› 立即申请
- Admin cum Customer Service
- Engineering
- Bayan Lepas
-
MYR 3K /Month
› 立即申请
- Software Developer
- Information Technology
- Kuala Lumpur
-
MYR 4K /Month
› 立即申请
- PHP Software Engineer
- Engineering
- Kuala Lumpur
-
MYR 4K /Month
› 立即申请
- PHP Software Engineer (Internship)
- Engineering
- Kuala Lumpur
-
MYR 800.00 /Month
› 立即申请
- HR Recruiter (Internship)
- Human Resources
- Kuala Lumpur
-
MYR 850.00 /Month
› 立即申请
- Multimedia - Video & Marketing (Internship)
- Advertising & Marketing
- Kuala Lumpur
-
MYR 800.00 /Month
› 立即申请
- Graphic Design + Marketing (Internship)
- Advertising & Marketing
- Kuala Lumpur
-
MYR 800.00 /Month
› 立即申请
- PHP Web Developer
- Engineering
- Kuala Lumpur
-
MYR 4K /Month
//
//
//
//









